主成分分析の2種類の定式化



平均は原点に一致するとする。つまり、
各ベクトルのエントリは、^T")
さて、これらの
ある単位ベクトル
2種類の条件とは、分散の最大化と、残差平方和の最小化である。
分散の最大化で考える分散とは、

残差平方和の最小化で考える残差とは、
正射影したベクトル
2種類の条件のどちらを考えても、全く同じ
というのが、この記事で言いたいことである。
1.分散を最大化する
ベクトル
ということは、各 = 0")

 = 0")



よって、
つまり、 \boldsymbol{u}")
これら正射影ベクトルの長さ
^2")
を最大化する
を求めてみる。(でなく で割っても答えは同じ。)
で割っても答えは同じ。)

そこで、ラグランジュの未定乗数法を使い、
 = \frac{1}{N}\sum_n (\boldsymbol{u}^T \boldsymbol{x}_n)^2 + \lambda (1 - \boldsymbol{u}^T\boldsymbol{u})")
を最大化する。
そのためには、
}{\partial u_{d}}") を各
を各 について求め、
について求め、}{\partial u_{d}} = 0") を解けばよい。
を解けばよい。
偏微分を計算する前に、")
 = \frac{1}{N}\sum_n (\sum_d u_d x_{nd})^2 + \lambda (1 - \sum_d u_d^2)")
さらに細かく書き下す。
 = \frac{1}{N}\sum_n (\sum_d u_d^2 x_{nd}^2 + 2 \sum_d \sum_{d^\prime \neq d} u_d u_{d^\prime} x_{nd}x_{nd^\prime}) + \lambda (1 - \sum_d u_d^2)")
よって、
}{\partial u_{d}} = \frac{1}{N}\sum_n \{2 x_{nd}^2 u_d + 2 \sum_{d^\prime \neq d} (x_{nd} x_{nd^\prime}) u_{d^\prime} \} - 2 \lambda u_d")
を得る。
とおくと、 u_{d^\prime} \} = \lambda u_d")
を解けばよいことが分かる。
左辺は、次のように書き直せる。
 u_d + \sum_{d^\prime \neq d} (\frac{1}{N}\sum_n x_{nd} x_{nd^\prime}) u_{d^\prime} = \lambda u_d")
よく見ると、
") はベクトルの番目のエントリに関する分散で、
はベクトルの番目のエントリに関する分散で、") はベクトルの番目と
はベクトルの番目と 番目のエントリに関する共分散になっている。
番目のエントリに関する共分散になっている。
そこで、

なお、
 は、行列の第行第列の成分のことである。
は、行列の第行第列の成分のことである。
行列
これはさらに、下のように書き直せる。



となる。つまり、
はこの方程式を満たす。
ここで、最大化したかった分散を思い出す。
先ほどの方程式
を満たすについては、この分散の値はどのように書き直せるだろうか。
この分散を、細かく書き下してみると
^2 = \frac{1}{N}\sum_n (\sum_d u_d x_{nd})^2")
となる。その一方、
とおくことで、つまり
 u_{d^\prime} = \lambda u_d")
を得ていた。左辺が分散の式と似ている。そこで、この両辺に
 を掛けてみる。
を掛けてみる。 (x_{nd^\prime} u_{d^\prime}) = \lambda u_d^2")
両辺の
についての和を求める。 (x_{nd^\prime} u_{d^\prime}) = \lambda \sum_{d=1}^D u_d^2")
よく見ると、左辺は分散
と全く同じ式になっている。右辺は
が単位ベクトルであることより に等しい。
に等しい。つまり、
^2 = \lambda")
という関係式を得た。
は分散に等しくなるのである。
同じことは、分散の式を次のように変形しても導ける。
^2 = \frac{1}{N}\sum_{n=1}^N (\boldsymbol{u}^T \boldsymbol{x}_n)(\boldsymbol{x}_n^T \boldsymbol{u}) = \frac{1}{N}\sum_{n=1}^N \boldsymbol{u}^T (\boldsymbol{x}_n \boldsymbol{x}_n^T) \boldsymbol{u} = \boldsymbol{u}^T (\frac{1}{N}\sum_{n=1}^N \boldsymbol{x}_n \boldsymbol{x}_n^T) \boldsymbol{u} = \boldsymbol{u}^T (\frac{1}{N}\sum_{n=1}^N \boldsymbol{x}_n \boldsymbol{x}_n^T) \boldsymbol{u} = \boldsymbol{u}^T \boldsymbol{S} \boldsymbol{u}")
そして
を使えば
よって、
が導ける。
ところで、
は、線形代数で言うところの、行列
の固有方程式である。これを満たす固有ベクトル
は、いくつもある。がそれぞれに対応する固有値である。
しかし、欲しかったのは、分散を最大化する
・・・ということは、最大の固有値に対応する固有ベクトルが、求めたかった
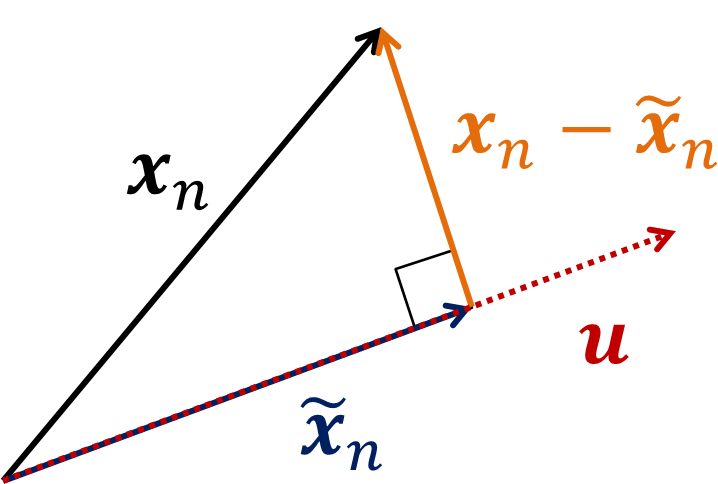
2.残差平方和を最小化する
よって、差ベクトルは \boldsymbol{u}")
この長さの平方和を最小化するような
 \boldsymbol{u} \|^2")
を最小化する
を求めたい。
足されている \boldsymbol{u} \|^2")
 \boldsymbol{u} \|^2=\boldsymbol{x}_n^T\boldsymbol{x}_n-2(\boldsymbol{u}^T \boldsymbol{x}_n)^2+(\boldsymbol{u}^T \boldsymbol{x}_n)^2 \boldsymbol{u}^T\boldsymbol{u}=\boldsymbol{x}_n^T\boldsymbol{x}_n - (\boldsymbol{u}^T \boldsymbol{x}_n)^2")
書き直すとき、
が単位ベクトルであることを使った。

ということは、解こうとしている最小化問題は
^2")
の最小化と等価で、これは、先ほど最大化しようとしていた分散に
 を掛けたものに過ぎない。
を掛けたものに過ぎない。つまり、全く同じ問題を解いていることになる。
なので、答えも同じ。
というか、ピタゴラスの定理で斜辺の長さが一定の状況に相当するので、
残りの2辺のうち一方の長さの2乗を大きくすることは、
他方の長さの2乗を小さくすることと等価になる。
(おわり)