Extracting per-topic temporal transitions of popular words from parallel corpora
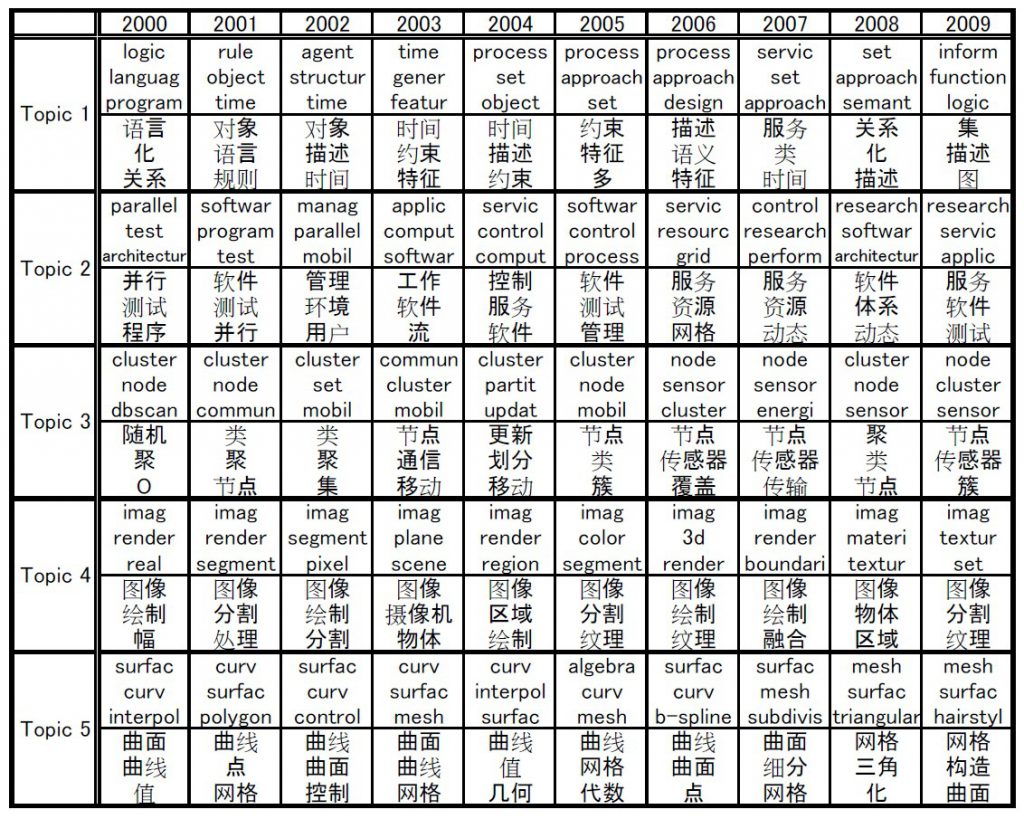
- We propose a new topic model [Masada+ PAKDD2011] for extracting temporal transitions of word probabilities for each topic.
- Our model is extended for parallel corpus analysis and is applied to Chinese-English abstracts of computer science papers.
- The years of the abstracts range from 2000 to 2009.
- We only show five among tens of the extracted topics.
- Each topic is represented by the top three Chinese and English words of large probability in each year.
- No Chinese-English dictionaries are used.
- This is a joint research with Prof. Atsuhiro Takasu in NII. The dataset was collected and cleaned up by Haipeng Zhang.